In the second blog post of this series, we talked about the dynamic nature of the Cloud Desktop Fabric™ – we saw how it effectively transforms Cloud Desktops into a global elastic utility, connecting users to high-performance desktops anywhere in the world. The Workspot Cloud Desktop platform makes it simple to provision virtual desktops for users globally, and achieve all the business agility benefits that go with that. If you missed the first blog in the series, where we define what The global Cloud Desktop Fabric architecture for Cloud Desktops is, have a look when you have a chance. It’s a real eye-opener for IT leaders about what is possible today.
The Virtual Desktop “Dial Tone”
You can fly off to some remote corner of the world you’ve never been before, walk out of the airport, and reach for your cell phone. These days, you are pretty confident that you can make a call or check your favorite feed – an everyday miracle we may not think about very much. If you’re like me, you have only a modicum of understanding about the hardware, software, networks, and other resources this feat requires, and chances are you have no idea who the local carrier is when you land in Lima, or Prague, or wherever you landed. You might think of this as your “dial tone”, meaning it just works wherever and whenever you need it (if you are a millennial: a phone used to be used just for voice communication, and it made a funny sound – a dial tone – that told you the system was ready for you to dial and connect to the world). Today we want to explore the question: Is there a “dial tone” for virtual desktops? In other words, is there a way to access your virtual desktops anytime, from anywhere in the world, and be able to expect the same kind of availability and reliability that the old-school dial tone delivered?
An Innovative Approach to the New Business SLA
Virtual desktops are the most mission-critical workload in the enterprise. If Office 365 is unavailable, you can’t access email, but you’ll live. If SAP is unavailable, you cannot access SAP. But if your virtual desktop is not available you cannot access anything. Zero productivity. Nada. We’ve heard that painful story too many times.
With legacy VDI operations, ensuring the availability of a VDI solution stack is complex. You have to make all the piece-parts – brokers, databases, servers, load balancers, and other infrastructure components – highly available. Even after doing all that, when things don’t function right, IT teams find out there’s a problem only when they start getting a flood of unhappy users calling into support. What a nightmare!
Workspot’s SLA for our turnkey cloud desktop service is industry-leading at 99.95%, but that’s just part of the story. The need for high-availability across cloud desktops, public cloud infrastructure, your network, etc.. is obvious. And although Workspot does not control all of that equation, our service monitoring capabilities can help IT teams quickly identify the source of a problem so they can take action faster, and stay on top of the overall business SLA.
Making sure that virtual desktops are highly available is one of the most important tasks of Workspot’s SaaS platform. We approach the critical task of delivering highly available and reliable Cloud Desktops through four innovative steps:
- Stateful client architecture
- Deep, real-time instrumentation
- Pro-active, real-time root cause analysis
- Pro-active, real-time blast radius analysis
Cloud Desktop High-Availability Is the Foundation for Business SLA
Stateful Client Architecture
A typical legacy VDI deployment contains multiple components deployed in highly available pairs — SQL servers, load balancers, portals, brokers, licensing servers, provisioning servers, etc. Multiple components are involved in every single user request, sometimes multiple times. It can take upwards of 30 handshakes among those components for a user to log in to their desktop. 30! Those 30+ steps include authentication, identifying resource entitlements, and then connecting users to the resources. Those 30+ steps happen every single time a user tries to connect because the legacy VDI clients are typically stateless. Through the power of compounding, even if each of the steps is 99% reliable, the overall sequence is now only 74% reliable (0.99^30 = 0.74). That’s only if everything works! If something does go wrong and a user is unable to login, how do you figure out which one of those 30 steps failed?
Unlike with legacy VDI, the Workspot clients are stateful. After the first login, the client stores much of the information needed. This means that when a user opens their Workspot client, not only do they immediately see what resources they can access (without even talking to the cloud), they also have the information needed to connect to those resources. Thus, Workspot reduces the user’s access to the resources they need to be productive to a single step. The control plane pushes any changes in entitlements or resources to the client in real-time. This stateful client architecture delivers much better availability. Even if the control plane is unavailable, the user can still connect to the resource (as long as the resource is available).
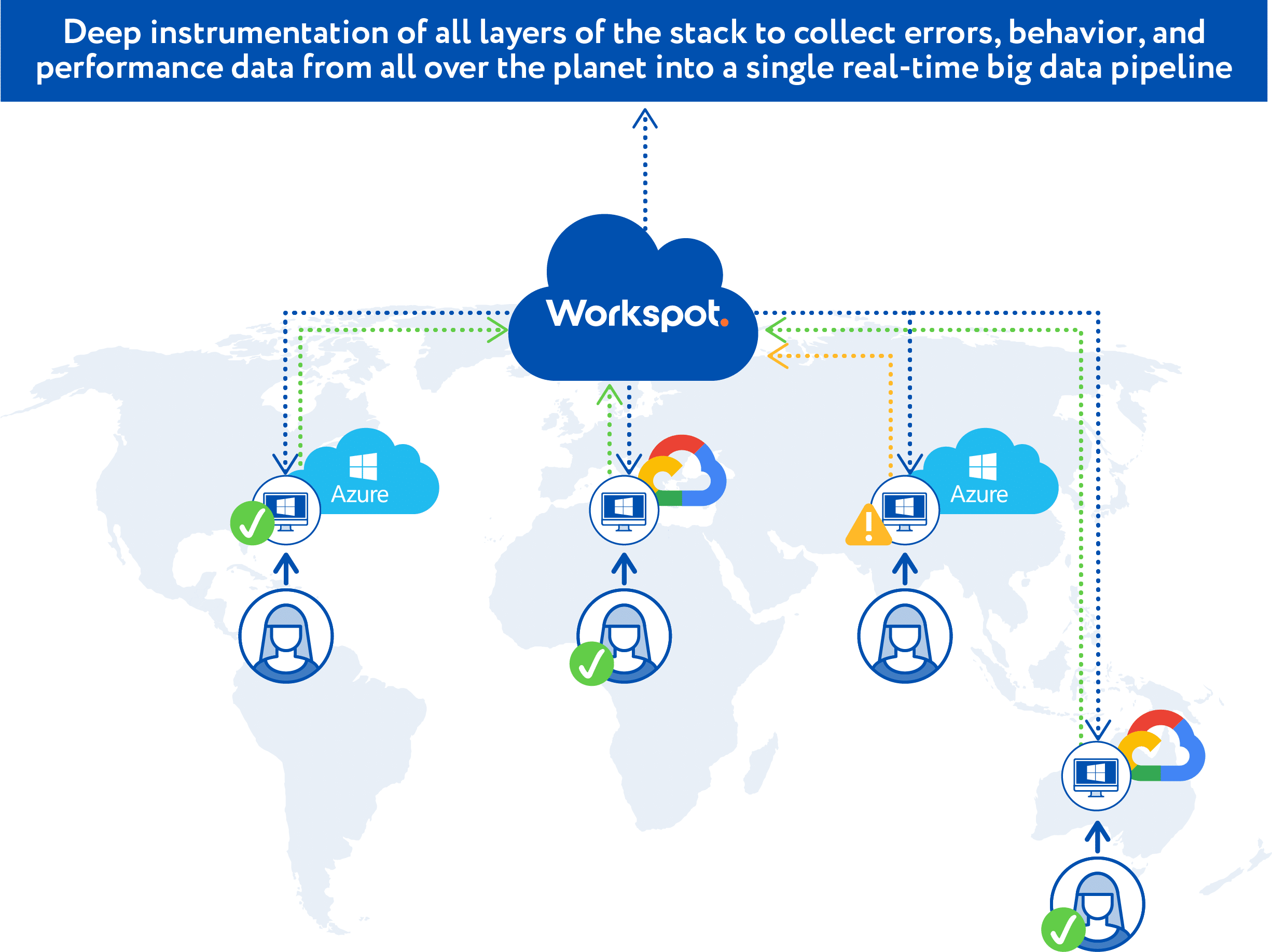
Deep, Real-Time Instrumentation
The key to maintaining a reliable service isn’t really about creating perfect configurations that never have problems… things can and will still go wrong. The fabric will have scalable clusters of infrastructure, performance tuning, and service failover; it is even able to quickly move users to different regions for disaster recovery. Here the key questions are: How proactively are the issues detected and managed? What was the actual cause of the problem? Who is about to be affected unless action is taken?
The first step in delivering a better SLA is to know what is going on everywhere. We start with the user’s point of view. If a user is unable to connect to their virtual desktop or is seeing poor performance (due to high latency or low bandwidth), we need to know about it in real-time. Next we need to know about everything in between that the user touches in order to connect to their virtual desktop – the network, the gateway, the region of the cloud and the virtual machine. Plus other infrastructure components that are needed to deliver a desktop experience like AD, DNS, etc. And all of this needs to happen in real-time. The cloud enables us to collect vast amounts of data in real-time.
Pro-Active, Real-Time Root Cause Analysis
The steady stream of Cloud Desktop monitoring data is not yet useful in itself. The important part is how it is effectively used, in real-time, to shine a light on the real source of problems. Here is where the Cloud Desktop Fabric comes into play. Because the Workspot control plane is involved in every step of provisioning and configuring the infrastructure, it maintains a model of all the dependencies between the underlying services. That means it can “understand” how the components affect each other.
Let’s take an example. One morning the system observes a spike in connection retry attempts, causing a delay for 5 users in Northern Europe. What might be going on?
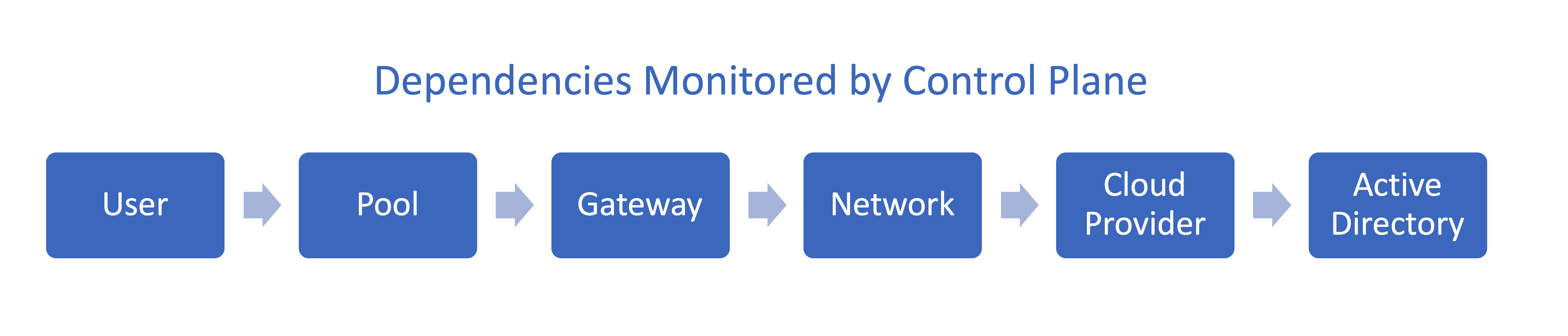
How can the dependency model help out here? The system “knows” that the pool of desktops involved in these events is mapped to a certain region’s cluster of gateways, that is also monitored as part of the fabric. Because all of the first attempts at connection went through Gateway A of the cluster, and then failed over to Gateway B, it can correlate this fact with events it has received directly from the monitoring agent on Gateway A.
Of course, these might simply be isolated events that don’t require any immediate action. What if, however… they are a proverbial “canary in the coal mine”, and there is a more serious threat? Consider some of the other possible actual culprits: Has Gateway A any problems with memory consumption, security certificate, or networking? Is it no longer able to access the customer’s AD to authenticate the user? Is there a problem in the customer’s own network? Whatever the real root cause, it can be determined in real-time thanks to the Cloud Desktop Fabric that can connect the dots much faster than a support engineer trolling through log files looking for clues.
Pro-Active, Real-Time Blast Radius Analysis
Once a root cause is identified, what then? Important questions to ask first are: What is the scope of the potential failures? Is it one user? One pool of users? An entire region? That same global dependency graph that is maintained by the control plane comes to the rescue again.
Sometimes we can “predict” failures based on infrastructure components going down. If a public cloud region is unavailable, all users within that region across multiple customers will be affected. We know that this is going to happen even if no users are logging in at that instant in time. Or if a gateway in a region is unavailable, we know that all users who generally connect through that gateway will have that load shifted to other gateways. At best it will strain the health of the cluster, or could even lead to users not being able to connect at all.
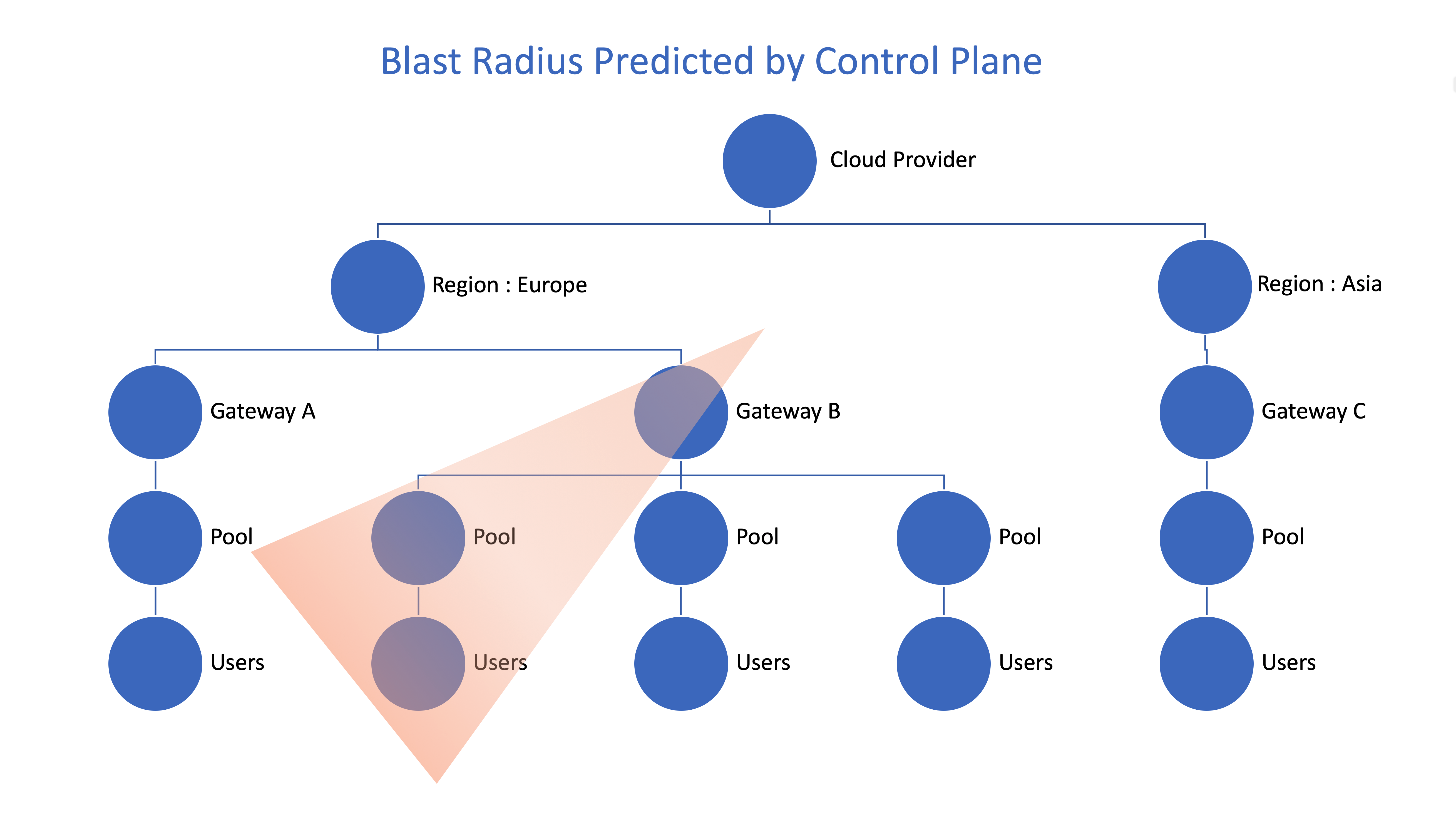
Depending on the root cause and the blast radius, pro-active steps to address the problem can be quickly taken. Additional gateways can be spun up dynamically. Automated maintenance operations can be triggered. The right people can be alerted!
The Global Dial Tone for Virtual Desktops: Only with Workspot
The consumers of a global, turnkey, cloud desktop service should now expect a “dial-tone” for virtual desktops; that is, users have the ability to connect to their cloud desktop or cloud GPU workstation from anywhere, at any time, and from a variety of devices, and experience outstanding performance. An IT administrator can expect cloud desktop provisioning to be fast, template updates to run smoothly, and expansion to new use cases around the globe to happen surprisingly quickly. With Workspot’s highly sophisticated instrumentation, root cause analysis and blast radius analysis, problems can be addressed quickly, if not proactively. Instead of needing to know exactly how this all functions, IT teams can be confident that there is an enterprise-ready, Global Desktop Fabric providing the virtual desktop dial tone – that just works.
Let’s talk about your enterprise requirements! Schedule a demo now.
Cloud Native Architecture




